General
Making MCP Tool Calls Smarter: A Practical Fine-Tuning Blueprint
Jul 16, 2025

If you’ve ever worked with multi-tool LLM systems especially within enterprise or DevOps workflows you’ve probably hit a wall with prompt engineering. The more tools you plug into your LLM, the messier the prompts get. Once you go past 10–20 tools, the token count balloons, the responses get less precise, and managing context becomes a nightmare.
That’s exactly what led me down the path of fine-tuning a custom model for MCP tool calls.
In this article, I’ll Walk you through a practical, hands-on guide to fine-tuning an LLM that makes smarter, cleaner, and more efficient tool calls. No fluff, no excessive theory just a clear blueprint, code included.
My goal? To help others avoid the pain I went through: bloated prompts, over-complicated tool selection, and unpredictable model behavior.
Along the way, I’ll share:
Why I chose fine-tuning over traditional prompt engineering
How I built and balanced a compact, high-quality dataset
What pitfalls I hit during training (hint: overfitting is real!)
And the exact steps I used to train and deploy a functional model
I’ve open-sourced everything — the dataset (
yashsoni78/conversation_data_mcp_100) and the model (yashsoni78/mcp_tool_model) from hugging face, so you can plug it into your own workflows or extend it as needed.
This is a practical blueprint designed for engineers, ML enthusiasts, and builders who are tired of tweaking prompts and want a scalable, token-efficient solution for tool use.
Section 2: What We’re Working With
Before diving into the code, let’s understand what exactly we’re fine-tuning and why the structure of the dataset plays such a critical role in making MCP tool calls smarter.
The Goal
The objective is to build an LLM that can:
Decide when to trigger a tool call
Select the correct tool from a set of predefined options
Handle conversational queries that don’t require tool calls gracefully
This eliminates the need to embed entire tool descriptions in prompts, making requests faster, cheaper, and more scalable.
Dataset Strategy: Quality > Quantity
Instead of training on a massive, noisy dataset, I chose a balanced and handcrafted dataset of just 100 examples:
Dataset Breakdown
| Example Type | Tool Name | Count || ------------------- | ----------------------- | ------- || Tool Call Example | get_vm_status | 20 || Tool Call Example | list_storage_buckets | 15 || Tool Call Example | create_support_ticket | 25 || Conversational Only | (No tool triggered) | 40 || Total | — | 100 |
This dataset is available here:
yashsoni78/conversation_data_mcp_100 · Datasets at Hugging Face
Lessons from Dataset Preparation
Before finalizing the dataset, I experimented with larger sources like:
alihmaou/Agents_MCP_Hackathon_Tools_List(too broad and inconsistent)Custom 1500-example tool call set (overfitted, hallucinated outputs)
Ultimately, I learned that a smaller, well-balanced dataset outperforms a larger, noisy one. It makes the model:
More stable
Less likely to hallucinate
Better at generalizing across similar tool patterns
Section 3: The Fine-Tuning Blueprint (Step-by-Step)
Let’s walk through the full process of fine-tuning your model — from preparing the data to training and evaluating the final version. I’ve broken it down into clear steps so you can follow along and adapt it for your own tool-call workflows.
The first step is to load the dataset from Hugging Face and clean it for training.
Step 1: Load and Pre-process the Dataset
Always inspect your dataset structure early. It prevents hidden issues during tokenization and model training.
Step 2: Data Cleaning & Formatting
You’ll need to ensure the data is in a structured prompt response format that’s ideal for LLM fine-tuning.
Step 3: Tokenize the Dataset
Step 4: Initialize PEFT (LoRA) Configuration and Fine-Tune the Model
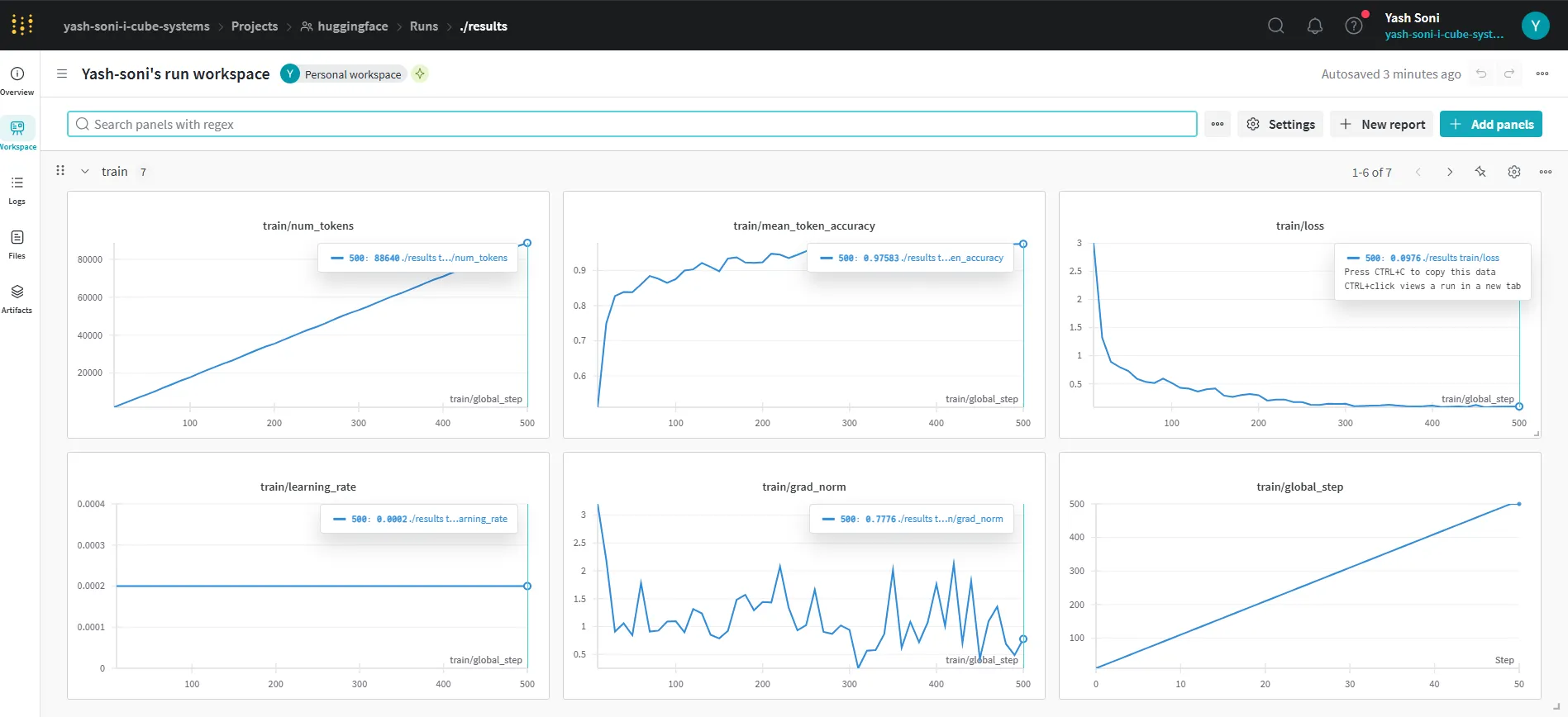
Training logs showing loss drop, token usage, and a consistent rise in token-level accuracy (up to 97.5%). Trained for 500 steps on a 100-example custom dataset.
As you can see above, the training stabilized nicely without spiking gradients or overfitting signs a good indication that the small dataset was well-balanced.
Step 5: Save and Share Your Model
Once the training completes, you can push it to Hugging Face:
model.push_to_hub("yashsoni78/mcp_tool_model")tokenizer.push_to_hub("yashsoni78/mcp_tool_model")
Section 4: Evaluation, Insights & What Worked
Now that we’ve fine-tuned the model, it’s time to evaluate how it performs on real conversations — especially across both tool-call triggers and natural chat responses. This section focuses on practical insights rather than formal metrics.
1. Manual Testing = Immediate Feedback
What to Look For:
Does it choose the correct tool?
Does it not hallucinate when no tool is needed?
Is the output formatted correctly?
2. Example Outputs
Let’s look at a couple of real generations:
Tool Trigger Example:
Input:User: Can you check the status of my VM?
Output:
Conversational Example:
Input:User: What’s the best way to reduce cloud costs?
Output:There are several strategies including optimizing VM usage, auto-scaling, and using spot instances. Would you like me to generate a report?
This confirms that the model is making intelligent decisions about whether to use a tool or not — which was the original goal.
3. What Didn’t Work (And why)
Like any real-world project, this wasn’t a straight line. Here’s what went wrong along the way:
Overfitting on 1500+ tool-only examples:
The model became too tool-focused and started hallucinating tool calls even in casual chats. Lesson learned: balanced data matters more than size.Using messy public datasets without clean-up:
Initial attempts usingalihmaou/Agents_MCP_Hackathon_Tools_Listintroduced inconsistent formatting and mismatched tool logic. Custom curation made all the difference.Too many tools = Too many tokens:
Packing all tools into a prompt broke token limit fast. Fine-tuning removed that bottleneck completely.
Final Thoughts
This fine-tuning effort turned a prompt-bloated, token-hungry LLM into a focused, efficient tool-calling engine.
Thanks to:
A carefully curated dataset
A well-balanced mix of positive and negative examples
Hands-on trial and error
…the model now understands how to act only when needed, reducing cost, improving latency, and scaling tool interactions gracefully.
Bonus: Try It Yourself
yashsoni78/conversation_data_mcp_100 · Datasets at Hugging Face
